Geo-data processing and analysis
We aim to develop efficient and robust methodologies and algorithms for parameter estimation and prediction, quality assessment, and statistical testing.
To study and monitor our changing Earth, including our living environment, we need observational data, i.e. measurements from all kinds of sensors, which may be on-board satellites, airplanes and ground-based — lots of data.
Generally we cannot directly measure what we want to know…, so, we do this indirectly: measuring other quantities which can be related to the parameters of interest through a mathematical model. Thereby, no measurement in practice is perfect, so we need to cope with errors in the measurements. Only then we can make inferences about the parameters of interest.
Our approach to geo-data processing, or observation theory, is world leading and based on decades of experience in research and teaching in geodesy and the wider geosciences in Delft.
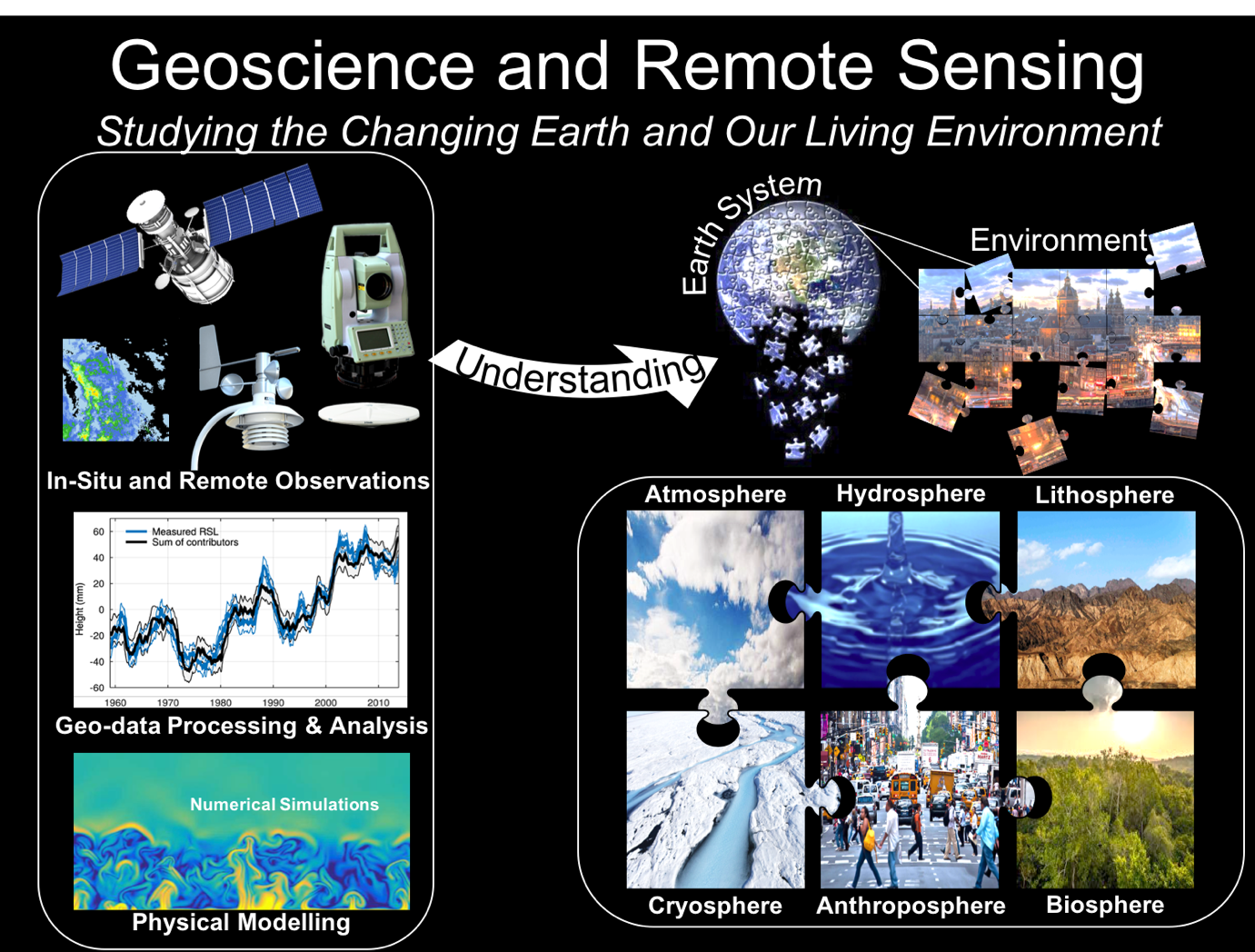
Geo-data analysis as one of the pillars – together with physical modelling – of Geoscience and Remote Sensing.
Our approach to geo-data processing, or observation theory, is world leading and based on decades of experience in research and teaching in geodesy and the wider geosciences in Delft.
In any geoscience application which involves observational data, the first step is to come up with an appropriate measurement set-up. For instance, when you want to measure deformations of the Earth’s surface at the level of a few millimeters per year, you need to think of the type and frequency of measurements which give you the required level of accuracy.
After the actual data acquisition comes the processing of the data. For that we need to set-up a functional model (relating the observations to the unknown parameters of interest) and a stochastic model (describing the quality of the observations, hence accounting for the uncertainties). Using the concepts of least squares, best linear unbiased estimation and prediction, parameters are estimated or predicted, and analyzed in terms of precision and significance.
Are we done? No, not yet. Can we really rely on our results? Are we sure that the models we applied are correct? Are we sure that we (or our measurement system) did not make any mistake? Here is where statistical hypothesis testing comes into play. It is applied in order to decide whether the so-called null-hypothesis (our default model) is correct, or an alternative hypothesis about the model and data is to be used.
Let’s finally look at the challenges ahead. Firstly, there is the ever-increasing amount of data (big data!), bringing not only the problem of computational load, but also that of automated extraction of the information of interest with proper quality assessment. This is where machine learning and data mining enter the scene. Another challenge lies in the combination of data from multiple sensors, with different and often complex functional and stochastic models. And then there is the issue of trust, referred to as reliability, or integrity. More and more applications are safety-critical, think of automated driving of vehicles and detecting geo-hazards. This means that we need to be able to guarantee that the parameter estimates are close to the actual, or true values, and not far off by an incidental fault in the measurement system. For that we need to solve a complex testing problem with many alternative models to account for all the potential faults and threats.